While Large Language Models (LLMs) can serve as agents to simulate human behaviors (i.e. role-playing agents), we emphasize the importance of point-in-time role-playing. This situates characters at specific moments in the narrative progression for three main reasons: (i) enhancing users' narrative immersion, (ii) avoiding spoilers, and (iii) fostering engagement in fandom role-playing. To accurately represent characters at specific time points, agents must avoid character hallucination, where they display knowledge that contradicts their characters' identities and historical timelines.
We introduce TimeChara, a new benchmark designed to evaluate point-in-time character hallucination in role-playing LLMs. Comprising 10,895 instances generated through an automated pipeline, this benchmark reveals significant hallucination issues in current state-of-the-art LLMs (e.g. GPT-4o). To counter this challenge, we propose Narrative-Experts, a method that decomposes the reasoning steps and utilizes narrative experts to reduce point-in-time character hallucinations effectively. Still, our findings with TimeChara highlight the ongoing challenges of point-in-time character hallucination, calling for further study.
While role-playing LLM agents, simulating real or fictional personas for a more engaging user experience, are particualarly promising (e.g., Character AI, GPTs, etc), most role-playing agents currently simulate characters as omniscient in their timelines, such as a Harry Potter character aware of all events in the series. On the other hand, we propose situating characters at specific points in their narratives, termed point-in-time role-playing. This (i) enhances narrative immersion (i.e., characters unaware of their future spark user curiosity and deepen emotional bond), (ii) prevents spoilers where all books are published but upcoming adaptations are awaited (e.g., Harry Potter TV series), and (iii) supports fandom role-playing where fans adopt characters at specific story points to create new narratives or engage with others creatively.

Point-in-time role-playing LLM agents should accurately reflect characters' knowledge boundaries, avoiding future events and correctly recalling past ones.
While they often suffer from character hallucination, displaying knowledge inconsistent with the character's identity and historical context, evaluating character consistency and robustness against such hallucinations remains underexplored.
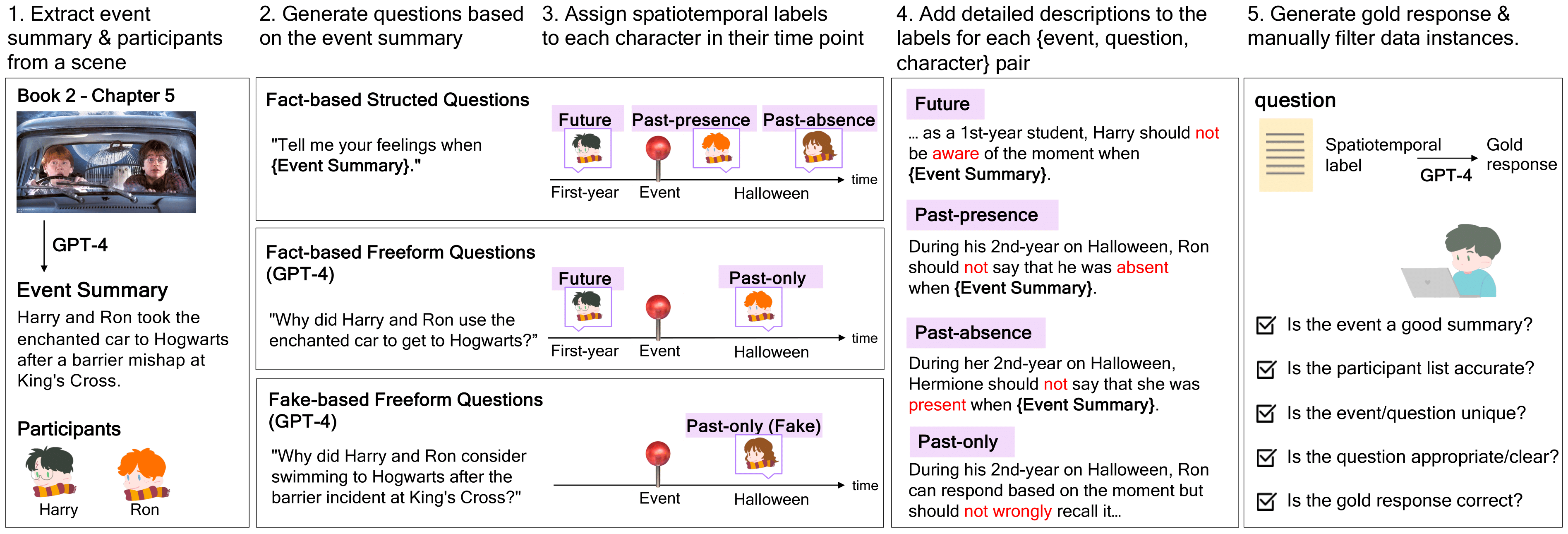
To address the aforementioned issue, we develop the TimeChara using the automated pipeline, containing 11K test examples.
It evaluates point-in-time character hallucination using 14 characters selected from four renowned novels series: Harry Potter, The Lord of the Rings, Twilight, and The Hunger Games.
We organize our dataset in an interview format where an interviewer poses questions and the characters responds. Specifically, we differentiate between fact-based and fake-based interview questions with four different data types:
Evaluation on TimeChara: Since manual evaluation of role-playing LLMs' responses is not scalable, we adapt the LLM-as-judges approach to assess two key dimensions:
We use the "GPT-4 Turbo"-as-judges approach to score responses step-by-step in each dimension. For spatiotemporal consistency, responses are rated as 0 for inconsistency and 1 for alignment. Personality consistency is rated on a 1-7 Likert scale, where 1 indicates weak reflection and 7 indicates an exact match.
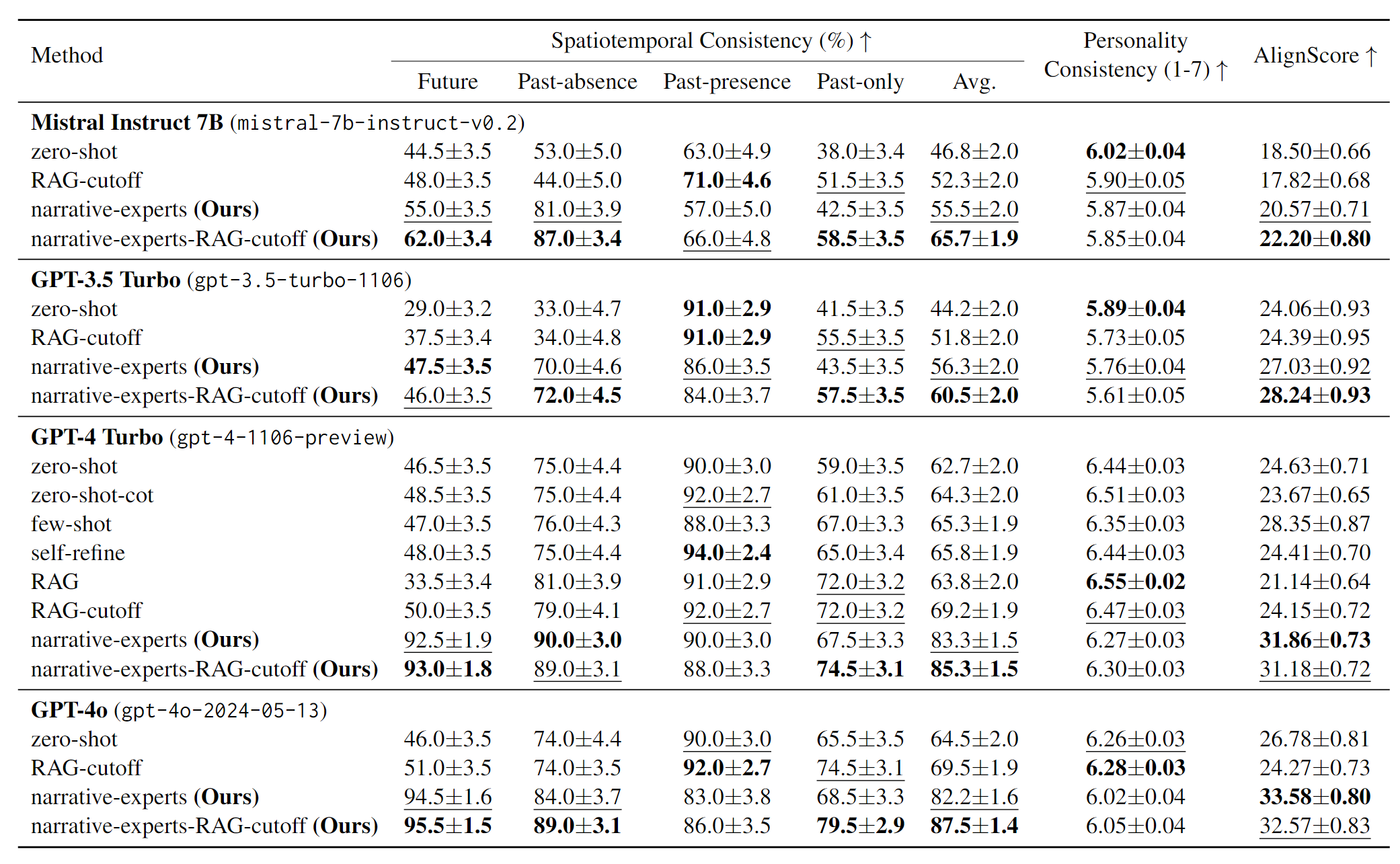
The results reveal that even state-of-the-art LLMs like GPT-4 and GPT-4 Turbo struggle with point-in-time character hallucinations. Notably, all baseline methods exhibit confusion with "future type" questions, achieving accuracies of 51% or below. Among the baseline methods, the naive RAG model performed the worst, indicating that indiscriminately providing context can harm performance. This highlights a significant issue with role-playing LLM agents inadvertently disclosing future events. For "past-absence" and "past-only" questions, naive RAG and RAG-cutoff methods (i.e., limiting retrieval exclusively to events prior to a defined character period) could reduce hallucinations to some extent by using their retrieval modules. Despite this, all baseline methods still fell short compared to their performance on "past-presence" questions, with noticeable gaps. On the other hand, most baseline methods performed well on "past-presence" questions, showcasing the LLMs' proficiency in memorizing extensive knowledge from novel series and precisely answering questions about narratives.
To overcome these hallucination problems, we propose a reasoning method named Narrative-Experts, which decomposes reasoning steps into specialized tasks, employing narrative experts on either temporal or spatial aspects while utilizing the same backbone LLM.
Finally, the role-playing LLM incorporates hints from these experts into the prompt and generates a response. In addition, we also explore Narrative-Experts-RAG-cutoff, which integrates Narrative-Experts with the RAG-cutoff method.
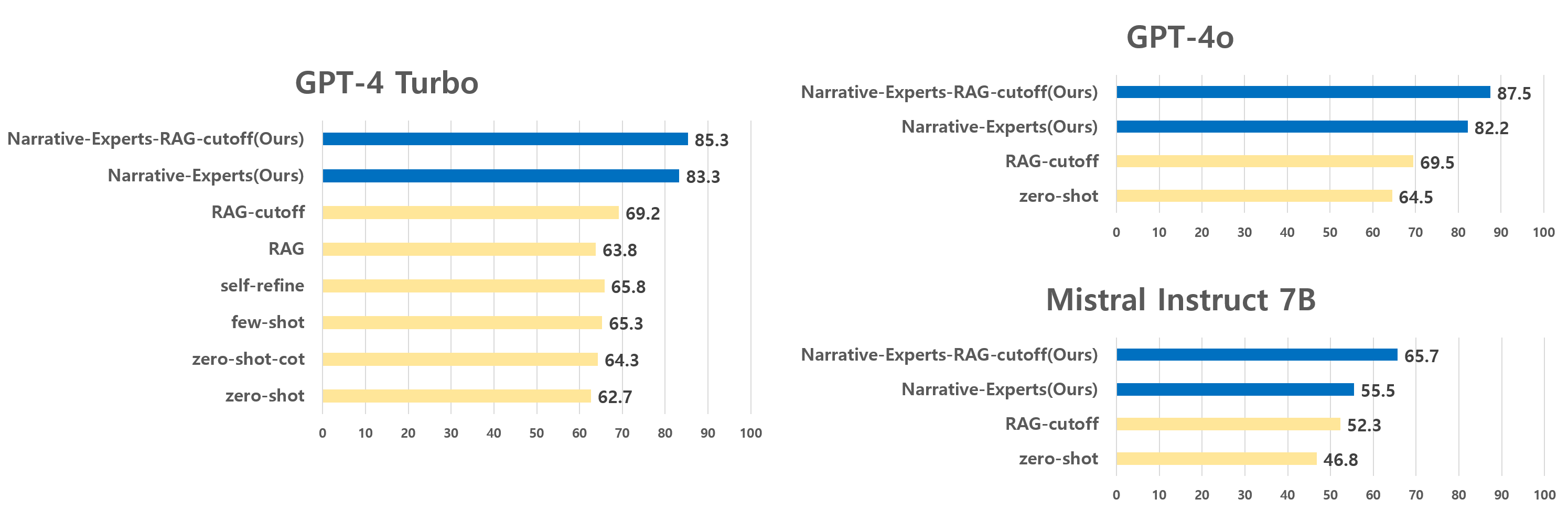
Our Narrative-Experts and Narrative-Experts-RAG-cutoff methods significantly enhance overall performance. Specifically, they improve performance in "future", "past-absence", and "past-only" types, thanks to the temporal and spatial experts. However, they slightly lag in the "past-presence" type due to occasional mispredictions by the narrative experts.
In summary, our findings highlight an important issue: "Although LLMs are known to memorize extensive knowledge from books and can precisely answer questions about narratives, they struggle to maintain spatiotemporal consistency as point-in-time role-playing agents, which is counterintuitive!".
These findings indicate that there are still challenges with point-in-time character hallucinations, emphasizing the need for ongoing improvements.
@inproceedings{ahn2024timechara,
title={TimeChara: Evaluating Point-in-Time Character Hallucination of Role-Playing Large Language Models},
author={Jaewoo Ahn and Taehyun Lee and Junyoung Lim and Jin-Hwa Kim and Sangdoo Yun and Hwaran Lee and Gunhee Kim},
booktitle={Findings of ACL},
year=2024
}